 Cách dùng lệnh sort, uniq, paste, join, split
Cách dùng lệnh sort, uniq, paste, join, split
Bài viết này giới thiệu các bạn về cách dùng lệnh sort, uniq, paste, join, split trên hệ điều hành Linux.
1. Thao tác trên tập tin

Khi quản lý tệp, chúng ta cần thực hiện nhiều tác vụ, như sắp xếp dữ liệu và sao chép dữ liệu từ vị trí này sang vị trí khác. Hệ điều hành Linux cung cấp một số tiện ích thao tác với tệp cho chúng ta sử dụng khi làm việc với các tệp văn bản. Trong bài viết này, chúng ta sẽ tìm hiểu về các thao tác với lệnh sau:
- sort
- uniq
- paste
- join
- split
2. Lệnh sort
Lệnh sort được sử dụng để sắp xếp các dòng của tệp văn bản theo thứ tự tăng dần hoặc giảm dần, theo một khoá sắp xếp. Khóa sắp xếp mặc định là thứ tự của các ký tự ASCII (theo thứ tự bảng chữ cái). Cú pháp của lệnh sort:
sort <tuỳ chọn> <file>
Để xem các tùy chọn của lệnh sort ta dùng lệnh: man sort
Lệnh sort được sử dụng như sau:
| Cú pháp | Chức năng |
|---|---|
sort <file> | Sắp xếp các dòng trong tệp, theo các ký tự ở đầu mỗi dòng |
sort -r <file> | Sắp xếp các dòng theo thứ tự ngược lại |
Kết hợp hai tệp, sau đó sắp xếp các dòng và hiển thị ra màng hình:
cat file1 file2 | sort
Ví dụ: Sắp xếp các dòng trong file.txt theo thứ tự a đến z và ngược lại
[root@test1 ~]# cat file.txt
apple
child
safari
rain
nice
delay
hand
[root@test1 ~]# sort file.txt
apple
child
delay
hand
nice
rain
safari
[root@test1 ~]# sort -r file.txt
safari
rain
nice
hand
delay
child
apple
2. Lệnh uniq
Lệnh uniq dùng để bỏ các dòng liên tiếp trùng lặp trong một tệp văn bản rất hữu ích để đơn giản hóa hiển thị văn bản.
Lệnh uniq yêu cầu các dòng trùng lặp phải liên tiếp, nên chúng ta thường chạy sắp xếp trước, sau đó mới chuyển đầu ra thànhuniq`.
Để xóa các mục trùng lặp khỏi nhiều tệp cùng một lúc, hãy sử dụng lệnh sau:
sort file1 file2 | uniq > file3
Hoặc
sort -u file1 file2 > file3
Để đếm số lượng mục trùng lặp, sử dụng lệnh sau:
uniq -c filename
Ví dụ: Lọc các dòng trùng lặp trong file.txt
[root@test1 ~]# sort file.txt
apple
apple
child
child
delay
delay
hand
hand
nice
nice
rain
rain
safari
safari
[root@test1 ~]# uniq file.txt
apple
child
delay
hand
nice
rain
safari
Ví dụ: Đếm số lượng dòng trùng lặp trong file.txt
[root@test1 ~]# cat file.txt
apple
apple
child
child
delay
delay
hand
hand
nice
nice
rain
rain
safari
safari
[root@test1 ~]# uniq -c file.txt
2 apple
2 child
2 delay
2 hand
2 nice
2 rain
2 safari
3. Lệnh paste
Giả sử chúng ta có tệp chứa tên đầy đủ của tất cả nhân viên và một tệp khác liệt kê số điện thoại và ID nhân viên của họ. Chúng ta muốn tạo một tệp mới chứa tất cả dữ liệu được liệt kê trong ba cột: tên, ID nhân viên và số điện thoại. Làm thế nào chúng ta có thể làm điều này một cách hiệu quả mà không cần đầu tư quá nhiều thời gian?
Lệnh paste được sử dụng để tạo một tệp duy nhất chứa cả ba cột. Các cột khác nhau được xác định dựa trên các dấu phân cách.
Ví dụ: Dấu phân cách có thể là khoảng trắng, tab hoặc Enter.
Lệnh paste thường sử dụng các tùy chọn sau:
-ddấu phân cách: Chỉ định danh sách các dấu phân cách được sử dụng thay vì các tab để phân tách các giá trị liên tiếp trên một dòng. Mỗi dấu phân cách được sử dụng lần lượt; khi danh sách đã hết,pastebắt đầu lại ở dấu phân cách đầu tiên.-s: Nối dữ liệu theo chuỗi chứ không phải song song. Theo chiều ngang chứ không phải theo chiều dọc.
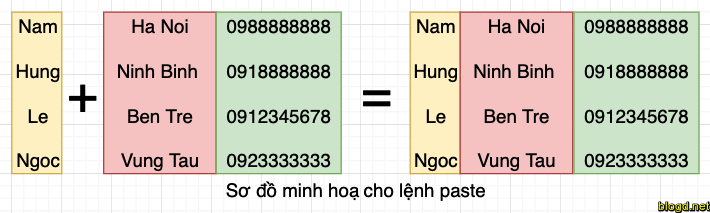
Lệnh paste được sử dụng để kết hợp các trường từ các tệp khác nhau, cũng như kết hợp các dòng từ nhiều tệp.
Ví dụ: Dòng một từ file1 có thể được kết hợp với dòng một của file2 , dòng hai từ file1 có thể được kết hợp với dòng hai của file2,...
Để dán nội dung từ hai tệp chúng ta sử dụng cú pháp:
paste file1 file2
Cú pháp sử dụng dấu phân cách khác nhau như sau:
paste -d, file1 file2
Các dấu phân cách phổ biến là 'dấu cách', 'tab', '|', 'dấu phẩy',...
Ví dụ:
[root@test1 ~]# cat phone
098-213-2344
096-345-6574
094-567-9043
091-238-8693
[root@test1 ~]# cat name
AA
BB
EE
CC
[root@test1 ~]# paste phone name
098-213-2344 AA
096-345-6574 BB
094-567-9043 EE
091-238-8693 CC
4. Lệnh join
Giả sử có hai tệp với một số cột tương tự. Chúng ta đã lưu số điện thoại của nhân viên trong hai tệp, một tệp có tên và một tệp có họ. Chúng ta muốn kết hợp các tệp mà không lặp lại dữ liệu của các cột. Làm thế nào để bạn đạt được điều này?
Để thực hiện việc trên bằng cách sử dụng phép nối, về cơ bản là phiên bản nâng cao của lệnh paste. Đầu tiên, nó kiểm tra các tệp có chia sẻ các trường chung hay không.
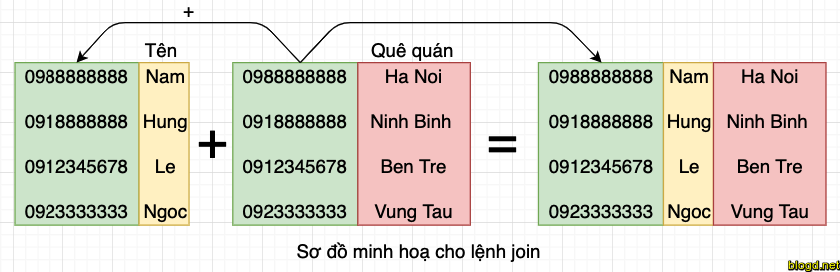
Để kết hợp hai tệp trên một trường chung: join file1 file2 và nhấn phím Enter.
Ví dụ:
[root@test1 ~]# cat file1
098-213-2344 AA
096-345-6574 BB
094-567-9043 EE
091-238-8693 CC
[root@test1 ~]# cat file2
098-213-2344 N
096-345-6574 L
094-567-9043 B
091-238-8693 H
[root@test1 ~]# join file1 file2
098-213-2344 AA N
096-345-6574 BB L
094-567-9043 EE B
091-238-8693 CC H
4. Lệnh split
Lệnh split sử dụng để chia (hoặc tách) một tệp thành các phân đoạn có kích thước bằng nhau để xem và thao tác dễ dàng hơn và thường chỉ được sử dụng trên các tệp tương đối lớn. Theo mặc định, lệnh split tệp thành các phân đoạn 1000 dòng. Tệp gốc không thay đổi và một tập hợp các tệp mới có cùng tên cộng với tiền tố được thêm vào được tạo. Theo mặc định,tiền tố x được thêm vào. Để chia một tập tin thành các phân đoạn, sử dụng lệnh split infile.
Để chia tệp thành các phân đoạn bằng cách sử dụng tiền tố, sử dụng lệnh: split infile <Tiền tố>.
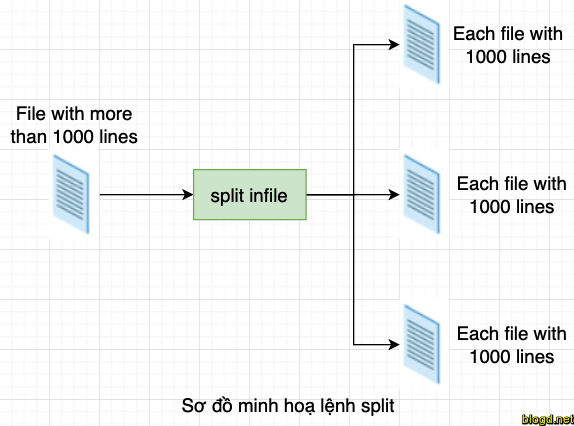
Chúng tôi sẽ áp dụng phân chia cho một tệp từ điển Mỹ-Anh gồm hơn 19.000 dòng:
wc american-english
19103 american-english
Chúng ta sử dụng wc (đếm từ) để báo cáo về số lượng dòng trong tệp. Sau đó, gõ:
split american-english
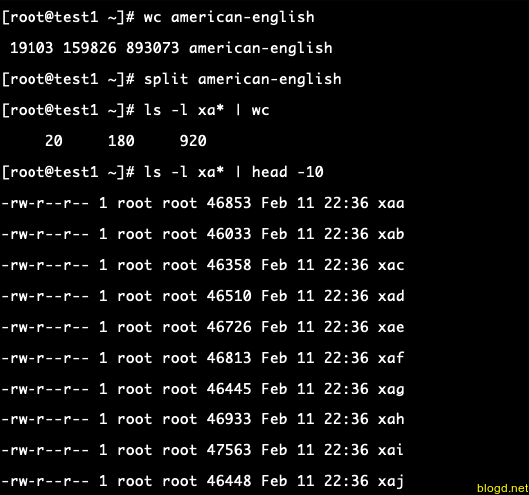
Cú pháp trên sẽ chia tệp american-english thành 100 phân đoạn có kích thước bằng nhau có tên 'xa*' . Phân đoạn cuối cùng tất nhiên sẽ là phần nhỏ hơn.